

生成 AI を活用した UI の自動生成 ~ プロンプト編 ~

はじめに
こんにちは。株式会社ラキールで DX 基盤開発を行う LaKeel DX Engine Group に所属する田村です。
現在、フロントエンド開発に高度なプログラミング知識を必要としない、ローコードビジュアル開発環境「Component Studio」の開発を行っています。
このたび、「Component Studio」では、生成 AI を利用した画面の自動生成機能「AI Navigator」をリリースしました。本リリースに関するプレスリリースは こちら をご覧ください。
本記事では、今回の開発で得たプロンプトエンジニアリングに関する知見を共有します。
AI Navigatorの細かいアーキテクチャに関しては、前回の記事「生成 AI を活用した UI の自動生成 ~ アーキテクチャ編 ~」で紹介しておりますので、そちらも併せてご確認頂けると幸いです。
前提知識
Component Studio / スマートウィジェット / UI コンポーネントとは?
Component Studio は、我々がスマートウィジェットと呼称している、画面部品を作成するための開発基盤です。

AI Navigator では、LLM にユーザの指示を解釈させ、UI コンポーネントを自動で選択・配置させることで、ユーザの指示に即したスマートウィジェットの自動生成を実現しました。
LLM / プロンプトとは?
LLM(Large Language Models)は日本語で大規模言語モデルと呼ばれ、様々な自然言語処理タスクで利用されています。
今回は、スマートウィジェットを構成する情報(UI コンポーネントの配置・プロパティ設定データなど)を出力させるために GPT-4o を利用しました。
RAG とは?
RAG(Retrieval-augmented generation)とは日本語で検索拡張生成と呼び、予め用意したデータベースを利用することで、LLM の学習データ(LLM が習得している知識)にない情報を LLM で利用可能にする技術です。
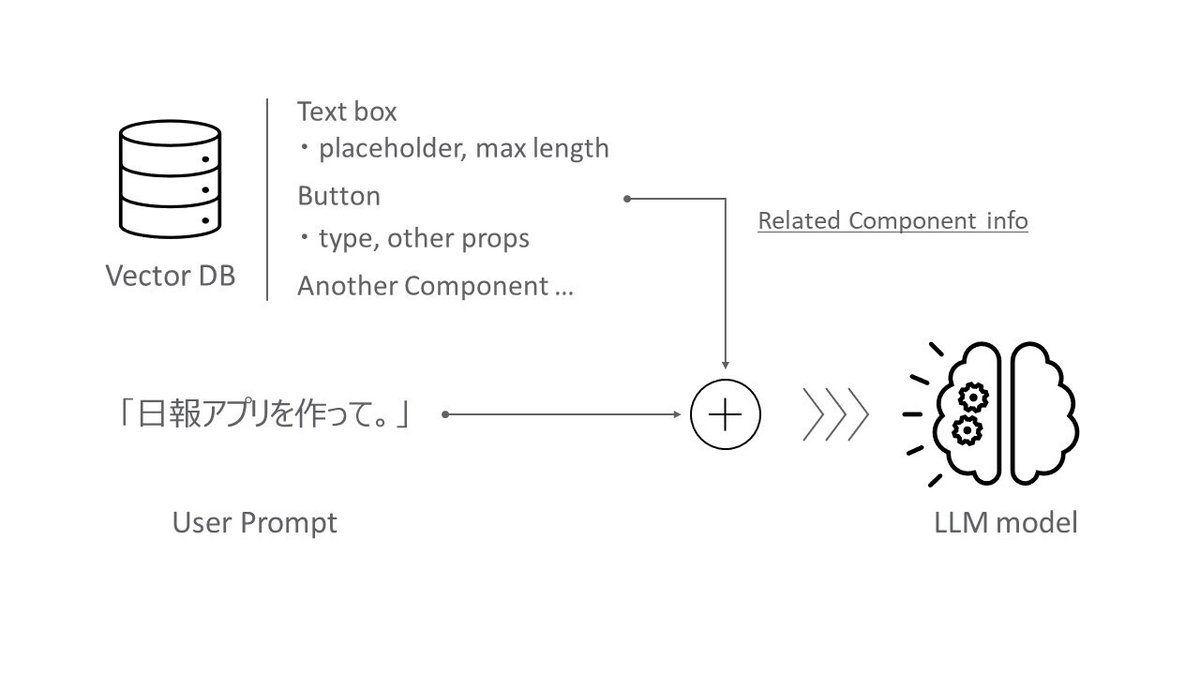
RAG では主に Vector DB を利用します。セマンティック検索により指示に関連した情報を取得しプロンプトを補強します。
今回は、ユーザの入力したプロンプトに近しい機能を持つ UI コンポーネントを選択するために、RAG を用いました。
RAG には、OpenAI の FileSearch を利用しています。
プロンプト開発における基本的な考え方
まずは、プロンプト開発における基本的な考え方から説明していきます。LLM の仕組みや特性を知ることで、自然と精度の良いプロンプトを記述することが可能となります。
LLM の基本的な仕組み・注意点
LLM は深層学習をベースとします。入力値と学習済のモデルから、出力値を推論します。「なぜその値だと高精度か」は考慮せず、単に間違いの少ない値を探索します。LLMのパラメータ数は膨大なため、獲得した値を解析して推論の根拠を示すことは困難です。

LLM ではプロンプトの行を入れ替えたり、言い回しを変更しただけで出力が大きく変化する場合がありますが、その根拠を把握することは不可能です。
「入力文からどういった出力文が得られるのか?」は、実際に推論させなければ判明しません。プロンプト開発の際は、修正に伴って発生する出力精度の変化や、機能性の低下に気を付けながら仮説検証のループを繰り返して進めましょう。
LLM の入出力特性と学習データ
LLM の特性を把握すれば出力をある程度コントロールすることが出来ます。この時「LLM が何を学習しているか?」を考えると把握しやすいです。
1. 特定の回答パターンの存在
チャット型 LLM は、入力に続く単語の出現確率を学習します。
例えば、「yes or no で回答してください。 カレーは飲み物である。」と質問をした場合、基本的に「はい」か「いいえ」で回答が始まります。これは同様の形式に対し、そう答えているデータが多いからと考えられます。
LLM の入出力関係にも特定の回答パターンは存在し、それらは学習データから推測することも可能です。この入出力パターンを多く知ることで、LLM の活用の幅を広げることが出来ます。
2. 学習データに存在する情報に影響される
LLM は、学習データに基づいて文章・単語の理解力を獲得しています。
例えば、独自のフォーマットやあまりメジャーではないプログラミング言語は上手に処理することが出来ません。また、仮に2015年以前のデータで LLM が学習されていた場合は「マジ卍」の卍は、かつての若者言葉の一部ではなく、仏教的な意味合いでのみ解釈されてしまうでしょう。
学習データの中で単語がどのように利用されているかを意識することで、表現の揺れを抑えたよい出力結果を得ることが出来ます。
3.知識はあるが、知恵は持たない
LLM は、あくまで入力文に続く次のトークンを予測するシステムです。数値演算のような知恵を厳密には表現できません。

基本的な計算が行えるのは、学習データに同様の問題を含んでいるからです。LLM は何でもできる訳ではないため、上手に活用しましょう。
出力トークンと処理時間・料金
LLM の利用に際し、出力トークン数を削減すると以下の恩恵が得られます。
LLM の生成速度は出力トークン数に依存するため、生成時間が短縮される
LLM を外部サービスで利用する場合、利用料金が削減される。
LLM の生成では、出力結果を含めて次のトークンを繰り返し予測するため、出力したトークン数に応じて時間が増加します。
例えば、今回利用した GPT-4o では 1000 トークンあたり $0.005(約0.7円)の料金と、 12秒前後の処理時間が発生します。
処理速度・料金面から、無駄を省き効率的な出力を求めることが重要です。
プロンプトの設計
それでは今回作成したプロンプトに関して解説していきます。AI Navigator プロンプト利用フローを以下に示します。

システムプロンプト
システムプロンプトとは、チャット型 LLM がどのようなタスクを行うかを定義するプロンプトで、チャット型 LLM のすべての振る舞いに影響します。主に静的なルールや手順を記載し、正確に記述・管理することが重要です。
プロンプトテンプレート
プロンプトテンプレートとは、LLM がタスクを実行するのに必要な背景情報とユーザの指示を動的に統合するためのテンプレートです。システムプロンプト適用時に不明な情報を LLM の入力へ付加するために用いられます。
関連するUI コンポーネントの仕様情報
UI コンポーネントの仕様情報(役割、プロパティの設定)を、RAG を利用して指示に関連した UI コンポーネントの情報のみ入力に利用することで、トークン数を抑えることが出来ます。DB 保存時に数百トークン毎でチャンク化するため、情報を凝縮して記述すると精度が高まります。
システムプロンプトの書き方
AI Navigator で用いたシステムプロンプトの構成に関して説明します。
1.指示 + マークダウンによる構成
今回の AI Navigator では、 システムプロンプトの形式に指示 + マークダウンの形式を採用しました。その理由は以下の2点からです。
(1) LLM への学習データとして多く用いられていそうなフォーマット
(2) マークダウン特有の記法のトークン数が少なく簡潔に記述できる
人が見て分かりやすい文章は、単に保守性が高いだけでなく LLM の解釈精度も向上します。また、一般的な書式を使うことも効果的です。それらは、LLM が正しく文書構造を学習している可能性が高いためです。

2.記載ポジションの重要性
LLM は最初と最後の文章を特に重要視するという説があります。
そのため、文頭には LLM に要求する全体的な振る舞いの「指示」を以下のように記述します。
・・・(指示の部分)・・・
要求文にしたがってスマートウィジェットを作成し, 回答様式に従って返答をしてください。 回答様式に反する回答は禁止します。インターフェースに関わるような厳守させるべき制約はシステムプロンプトの最後に記述しました。
・・・(インターフェース部分)・・・
# 回答様式
1. 生成したDataBlocksをスクリプトブロック内に記述
2. それ以外の文章を返答しないでください。
notes: 追加の回答様式が存在する場合は, その範囲で回答してよい。<EOL>3.前提条件は箇条書き
今回の開発では、タスクを遂行するのに必要な前提条件(ルールや、 実行手順)を定義する際、以下のように箇条書きを用いて簡潔に記述しました。
## 平面とセルの関係
ピクセル平面をセルに分割する方法を以下に示します。
1. 縦軸を40ピクセル単位の行に分割します。
2. 横軸を15個の列に分割します。
3. 行列のインデックスは0から始まる, 離散値です。 列インデックスの最大値は39となります。マークダウンで一般的に使われているため、高い精度が出やすい事に加え、通常の文章と比較して、保守性も担保することが出来ます。
4.ルール + サンプルによる精度向上
ルールが複雑なことから、LLM の出力にうまく反映されない・出力にムラが出る場合は、ルールと共にサンプルを示すことで精度を向上します。
この手法は強力で「Few-shot prompting」とも呼ばれており、独自のデータ構造を理解させることも出来ます。

5.回答様式による速度向上
以下の2点から、回答様式を定義し遵守させることは非常に重要です。
(1) LLM からの出力を解析しやすくするため
(2) 出力トークン数を削減するため
LLM の出力は自然言語のため、回答をシステムで利用するためには、解析処理が必要です。回答様式を厳密に定義することで、情報を制御し効率的な解析が可能になります。
# 回答様式
1. 生成したDatablocksをスクリプトブロック内に記述
2. それ以外の文章を返答しないでください。
notes: 追加の回答様式が存在する場合は, その範囲で回答してよい。上記の場合、コードブロックの始まりと終わりのグレイヴ・アクセントが認識できればデータを抽出することが可能となります。また、余分な文章も出力されないため、トークンを削減できます。
プロンプトテンプレート設計
入力プロンプトを生成するためテンプレートについて説明します。AI Navigator実行時の動的な情報は以下の3要素となります。
現在の配置状況
編集の指定コンポーネント
ユーザの指示
これらの要素をテンプレートによって結合することで、より柔軟で正確な出力を行わせることが可能となります。
# 現在のレイアウト
\```DataBlocks
${current_placement_info}
\```
上記のレイアウトに対して修正してください。
# 要求文
${user_prompt}
# 追加の回答様式
結果は${output_limit}分割してDataBlocksで出力します。
1. まず最初の${output_limit}つまでを出力してください。
2. 続きを要求された場合, 必要であれば出力してください。Component StudioがLLMを呼び出す際に、上記の変数の部分がシステムによってはめ込まれ、最終的なプロンプトが生成されます。
現在のレイアウト
編集画面に配置済みのコンポーネント情報をプロンプトに追加するために利用されます。主に、既存のレイアウトを編集する際に活用されます。
要求文
このセクションはユーザが入力した指示を記載するセクションとなります。
追加の回答様式
動的に回答様式を変更したい場合、このセクションを利用します。今回はトークン上限回避のために利用しました。トークン上限は、利用モデルによって異なるため、保守性の観点から今回はテンプレート側に記載しました。
トークン上限回避の分割出力
現在、一般に提供されているLLMサービスでは、入出力トークン数に制限が存在する場合があります。
UI コンポーネントが数十個を超えるような出力の場合に、Open AI APIの上限を超えることがあったため、1回のAPI呼び出しで出力するコンポーネント数を指定し、分割出力することで上限を回避しました。

APIの初回実行後、同じスレッドに続きを要求する固定プロンプトを継続的に投げることで、分割出力を実現しました。
その他の開発・記述テクニック集
その他、有効な開発・記述テクニックを説明します。
プロンプトの適応レベルテスト
以下の方法で、LLMがプロンプトをどれだけ理解しているか確認できます。
指示文を「〇〇に関する質問に答えよ。」に差し替える
テスト文言を投げる
// スマートウィジェットの座標に関するテストの例
1. Componentを配置する座標系を図示せよ。
2. 2つのコンポーネントを配置し, 図示せよ。
// コンポーネント配置に関するテストの例
1. 画面サイズを 400px * 150px とします。画面の中央にコンポーネントの中心が来るように1つ配置してください。 コンポーネントのサイズは3*2とします。
2. (x,w)=(39,2) となるコンポーネントを配置してください。
3. (x,w)=(-1,2) となるコンポーネントは配置可能か答えよ。
// UI コンポーネントのプロパティ理解に関するテストの例
1. CsBaseText が持つプロパティを教えて
2. Form系のコンポーネントを一覧表示して上記は、実際にプロンプト開発に用いたテストです。これらのテスト文言で認識精度を確認しながら進めると効率的に開発できます。
プロンプトの具体性を上げる方法
精度が悪い場合は、曖昧な表現(多義語や指示語)を避け、修飾語や固有名詞を用いて具体的に記述することで精度を向上させることができます。具体的には以下のような手法が考えられます。
1つの単語は1つの意味に限定して使用
「その値」⇒「colorの値」のような明示的表現
notes(注釈)や鍵括弧などのアノテーション
※ 例えば、「要求文に従って○○しなさい。」というシステムプロンプトの場合にユーザの入力をうまく拾ってくれない時、以下のように
// テンプレート
要求文「(ユーザの入力を埋め込む)」鍵括弧を用いて要求文がどこかを強調することで認識精度が向上する。
出力結果の揺れを防ぐ分岐定義
LLMは、プロンプトに記載されないことは良くも悪くも勝手な解釈で処理します。
例えば次の制約の場合、値が未設定の場合が定義されていません。
### DataBlocks の制約とスキーマ
スキーマに従ってコンポーネントの配置を表現します。
1. DataBlockでは値のみを記載し,改行を用いて各プロパティ値を区分する。
2. ComponentIdから順に値を表示しま。
3. 各データブロックの境界は空行を用いる。この場合、LLMは未設定の値を、空行 / "" / null / undefined などで表現します。出力毎に変化する場合、解析処理の実装に無駄が生じます。
4. 値が未設定の場合はundefinedと表示この問題は、上記の制約を課しハンドリングすることで解決しました。
LLM の出力が意図せず複数パターン見られる場合は、エラーハンドリングのような意識をもって修正を施すとよいでしょう。
おわりに
LLM はブラックボックスであり、プロンプトの仮説検証を行う過程は、脳をリバースエンジニアリングしているかのような楽しさがありました。AI Navigator の開発期間は非常に短期間でしたが、数多くの工夫を凝らすことで、AIによるレイアウトの自動生成を実現することができました。
また、開発当初はプロンプトエンジニアリングに不慣れでしたが、開発を進める中で、より効果的な方法を見つけることができました。今後の開発で、これらの知見を活かしてさらなる精度向上を目指していきたいと思います。
大量の入出力項目を持つウィジェットの生成に関しては、精度やスピードにまだ課題がありますが、複数の LLM エージェントを並列で稼働させることや、最新のプロンプト技術を適用することで、さらなる改善と発展を目指していきます。